Минусинск ломает Matrixnet
Disclaimer(отмазка): cлегка ощущаю себя городским сумасшедшим — в очередной раз указываю инженерам Яндекса на ошибки в алгоритмах. Но, честное слово, seo-аудит с указанием на НПС-мерцание — не моих рук дело 🙂 Тем не менее, возьмусь утверждать, что алгоритм Минусинск входит в полное противоречие с основным алгоритмом ранжирования Яндекса — Matrixnet.
В чём суть MatrixNet?
Я уже пытался занудно рассказывать о том, что из себя представляет Матрикснет, теперь попробую разъяснить попроще. На пальцах.
Для обучения алгоритма инженеры Яндекса раздают асессорам, допустим, мешок яблок разных сортов. И просят их оценить вкус этих яблок по 5-бальной шкале. Асессоры коллегиально приходят к решению, что яблоки сорта Ред Делишес вкуснее сорта Голден Делишес и тем более Семеренко или упаси бог Антоновки.
Почему одни яблоки должны быть априори лучше других во всех случаях жизни науке не известно, но с момента вынесения вердикта асессорами MatrixNet считает, что красные сладкие яблоки лучше менее сладких, но жёлтых и уж тем более зелёных и кислых.
То, что мне утром в больницу другу нужны одни яблоки, вечером для шарлотки другие, а завтра себе поесть третьи — инженеры Яндекса особо не задумываются. Более того, они с юношеским задором пытаются на асессорских оценках яблок отсортировать заодно киви или лимоны… Но это я немного отвлёкся на врождённые пороки Матрикснет.
Для продолжения разговора важно лишь то, что после учёта мнения профанов асессоров Матрикснет пытается отсортировать яблоки в соответствии с этим мнением, т.е. так, чтобы Ред Делишес оказался как можно ближе к началу:

А что делает алгоритм Минусинск?
В результате применения алгоритма Минусинск сайт, на который оптимизаторы не очень удачно приобретали SEO ссылки, теряет в выдаче позиции абсолютно по всем запросам. В том числе и по навигационным. То есть по тем запросам, по которым на первом месте должен находится этот сайт и никакой другой.
Например, купил я в неком Фирменном центре Бош и Сименс бытовую технику. И возникли у меня некоторые сомнения в качестве одного из приобретённых предметов. Если я поищу в Google название указанное в накладной — ООО «Эдил Импорт», то найду искомое на первом месте:
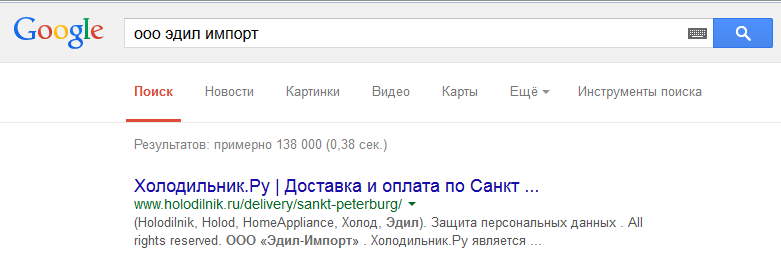
А вот если я поищу его в Яндексе, то тоже найду нужный мне сайт на первом месте. Только не на первой, а на третьей странице выдачи:
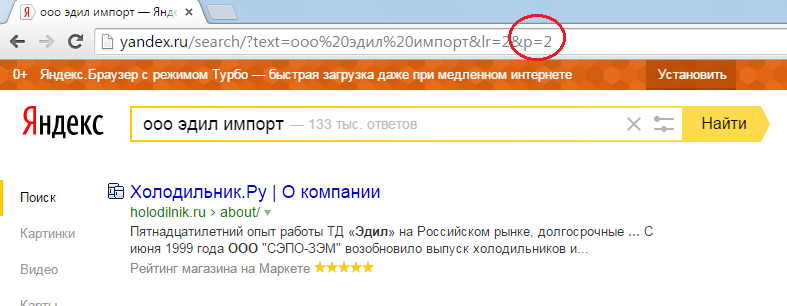
Таким образом можно сделать два вывода:
1. Инженерам Яндекса стало наплевать на pFound
2. Минусинск работает как постфильтр, который отрабатывает после MatrixNet. И при этом можно допустить, что сайты для наказания отобраны вручную.
Корень зла не в SEO-ссылках, а в коммерческих факторах ранжирования
Я не зря писал в начале этой заметки об ошибочности попытки ранжирования лимонов после обучения алгоритма МатриксНет на яблоках. Если совершить звонок по горячей линии Бош в России, то сюрприз-сюрприз, выяснится, что магазин, в котором я купил бытовую технику ни разу не фирменный и Бош к нему никакого отношения не имеет.
По злой иронии судьбы я не хотел покупать нужную мне технику в Холодильник.ру, а купил в ООО Эдил-Импорт. То есть там же, но в каком-то не очень афишируемом магазине. Не разобрался в коммерческих факторах, да. Но может быть алгоритмы Яндекса умнее меня?
Давай посмотрим на скриншот из Яндекса. Там в снипете красуются гордые 5 звёзд от Маркета. Вот он:
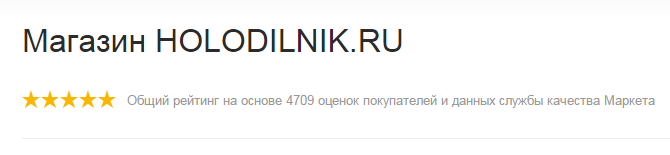
Как же так, магазин торгует как-то полуподпольно, а у него 5 звёзд от Маркета? Давай посмотрим на рейтинг более детально:
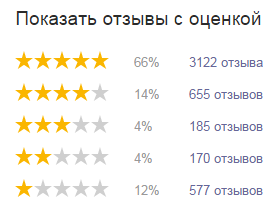
Если ты не забыл школьный курс математики, то легко посчитаешь, что каждый шестой оставивший отзыв на маркете поставил сайту Холодильник.ру 2 или вовсе 1 звезду. То есть это не только я — лох, штаны в горох, а каждый шестой был недоволен ООО Эдил-Импорт» чуть более, чем полностью. Каждый шестой, Карл! А служба качества Маркета даёт Холодильнику.ру 5 звёзд, игнорируя мнения пользователей.
Как думаешь, пришлось бы инженерам Яндекса изобретать Минусинск для наказания Холодильник.ру, если бы они умели адекватно считать рейтинг магазина по оценкам пользователей?
P.S: рекомендую прочитать заметку про другой злобный забавный косяк машинного обучения Внезапный диван леопардовой расцветки
Думы о Минусинске — алгоритме Яндекса
Сегодня, 27 мая, в Яндексе был обнаружен апдейт. Судя по тому, что из топов на характерные 20 позиций опустились несколько новых сайтов, можно сделать предположение, что это была вторая волна Минусинска. Или продолжение первой, не суть важно. Это предположение обязательно подтвердят вот тут.
После медитации над выдачей и плясками с бубном SEO-шников вокруг этого события я сделал несколько для кого-то банальных, а для кого-то видимо не очень, мыслей:
1. Инженеры Яндекса жестоки. Ссылочный апдейт 9 мая зафиксировал состояние ссылок на 1 мая. У всех, кто захотел исправиться в мае или после первой волны Минусинска, не было ни единого шанса.
2. Сайты, подвергшиеся воздействию алгоритма Минусинск, продолжают получать остаточный трафик с Яндекса — если сайт попал в число любимых пользователем, то высокие позиции этих сайтов сохраняются. Другими словами, Минусинск не затронул персонализированную выдачу. Что странно, так как владельцы сайтов последствий Минусинска могут и не заметить, если пострадавшая компания параллельно закупала контекстную рекламу.
3. Всего в нише может быть наказано не более 10 сайтов. Потому что при наказании 11-го сайта ранее наказанные сайты вернутся в 10ку. Если наказывают в одной волне по 2 сайта в нише, то всего возможно 5 итераций Минусинска. Это видимо будут править 🙂
4. Владельцы ссылочных бирж и агрегаторов поспешили отрапортовать (Sape, SeoPult, Miralinks в рассылке), что их ссылки самые не seo-ссылки в мире. Их понять можно — бизнес уничтожают, с этим надо бороться. Гораздо более печально, что
5. Некоторые оптимизаторы тоже поспешили рассказать всем, что они уже досконально изучили то, чего ещё не было и раздают налево и направо советы в стиле кто виноват и что делать Я, конечно, понимаю, что в эпоху контент-маркетинга главное прокукарекать первым, а там хоть не рассветай. Но такое кукарекание сразу после заката выглядит не очень профессионально, потому что
6. Самое интересное ещё впереди. Сначала, когда случится ссылочный апдейт в Яндексе. Когда станут видны последствия от снятия ссылок. При полноте и точности выявлении Яндексом SEO ссылок в 95% по оптимистичным оценкам инженеров Яндекса в любой большой бирже существуют десятки тысяч ссылок, которые Яндекс не считает SEO-шными и на которых вполне может держаться благополучие многих продвигаемых сайтов. А потом всё самое интересное продолжится, когда закончатся слишком очевидные кандидаты на санкции.
Мысль тривиальная. Яндекс может оценить естественный уровень прироста ссылок коммерческого сайта определённой тематики. Предположим, это 1-2 ссылки в месяц. Соответственно, если на 15-летний сайт стоит более 1000 ссылок, то не нужно знать ничего о природе этих ссылок — и без этого понятно, что их в 3 раза больше, чем положено. Значит можно резать не дожидаясь перитонита карать Минусинском. Особенно если бренд широко известен только в очень узких кругах.
Собственно тру SEO аналитика начнётся в тот момент, когда и если инженеры Яндекса осмелятся приблизиться с карательными операциями к границе естественного роста ссылок. То есть когда станет очевидным наказание именно за качество ссылок, а не за их количество, как это выглядит сейчас.
Расклейка 301-х редиректов в Яндексе
Пост из серии хозяйке на заметку, без каких-либо выводов.
Предыстория
Есть на продвижении с 2009 года сайт. Одна из групп запросов (пусть это будет аренда самолётов) оптимизировалась некоторое время на внутреннюю страницу сайта (/arenda_samolyotov.html). То есть на неё проставлялись внешние и внутренние ссылки, заказывался текст от известного копирайтера и сопутствующие тематические статьи от менее известного. Но. Примерно через пару лет, как я теперь подозреваю с началом использования для ранжирования поведенческих факторов, огромное преимущество в выдаче стали получать главные страницы. Помучившись безрезультатно месяц-другой с возвращением в ТОП внутренней страницы, я принял решение продвигать по этой группе запросов главную страницу сайта. И сделал 301-й редирект с внутренней страницы на морду. Редирект выполняется внутри скрипта, а не через .htaccess, то есть он гарантированно работает уже много лет.
Сама история с расклейкой 301-го редиректа
Вчера, 30 марта 2015 года, выполняя рутинные операции с выдачей, я обнаружил, что по основному запросу (аренда самолётов) той самой внутренней страницы (/arenda_samolyotov.html), вместо которой давным-давно продвигается главная страница сайта, в SERP‘е Яндекса отображается ссылка на эту внутреннюю страницу. С многолетним 301-м редиректом. Перейдя на эту страницу (/arenda_samolyotov.html) я, как и следовало ожидать, был перенаправлен на главную. То есть редирект продолжает исправно работать.
Разумеется, я не смог не посмотреть сохранённую копию (кэш) этой внутренней страницы. В кэше была обнаружена копия главной страницы. Поскольку при снятии позиций через XML ситуация не повторилась, я списал всё на легкий временный глюк.
Но сегодня история получила продолжение. В отчёте по снятым позициям, полученном сегодня, внутренняя страница стала присутствовать в SERP’е и по группе запросов (аренда вертолётов), по которой эта внутренняя страница (/arenda_samolyotov.html) никогда не продвигалась.
С ухудшением позиций и при том, что текстовых апдейтов последние два дня совершенно точно не было.
То есть в выдаче Яндекса главная страница сайта была заменена внутренней страницей с которой она склеена через 301-й редирект много лет.
Update:
Вспомнил ещё подобную историю. Там была полная многолетняя переклейка основного домена и домена с misspelling’ом. И зеркальщик Яндекса вдруг выбрал главным домен с ошибкой в написании. В результате в выдаче осталась только морда и позиции держались исключительно на ссылках. Правильно указать главное зеркало удалось только через Я.Каталог с упором на то, что деньги уплачены за домен в правильном написании. Позиции по основным запросам были утеряны на несколько месяцев, а количество проиндексированных страниц восстанавливалось больше года, то есть потери в трафике были огромными.
Вот такие пироги. С котятами.
Upd2:
Наиболее правдоподобная версия, которую предложил Сергей Кокшаров — проделки быстробота.
Фундаментальные особенности MatrixNet
После нашей беседы о фундаментальных особенностях MatrixNet я получил несколько острых наводящих вопросов, ответов на которые очевидно не хватало в моём рассказе. Выражаю авторам вопросов свою благодарность:
Постановка проблемы
Итак, постановка вопросов для нашего совместного обсуждения:
Вопрос из личного опыта: почему удаётся вывести в топ по довольно конкурентным запросам сайты с помощью ссылок, которые обычно оптимизаторами считаются мусорными?
Вопрос из наблюдения за выдачей: только ли за счёт поведенческих факторов держатся в топе сайты без заметного невооруженным глазом массива ссылок?
Свежий вопрос, поставленный перед оптимизаторами Яндексом: почему в топе с 23 февраля (не с 12 марта !!!) 2014 года по запросам например, юридической тематики, в топ попали молодые сайты практически без ссылок и без какого-либо заметного трафика до и надолго ли они там?
Или другими словами это баги (ошибки) или фичи (особенности) MatrixNet?
Эти все вопросы можно свести к одному единственному: почему не падает pFound при отказе от использования ссылочных факторов в функции ранжирования или при отсутствии у документов поведенческих факторов?
Через тернии к звёздам
Ответ на этот вопрос очень простой, но подбираюсь я к ответу на него достаточно сложно, буквально через тернии к звёздам и в онлайн рассказе я сделал это крайне плохо. Попытаюсь исправится после дополнительной подготовки. И ещё раз всем спасибо за уточняющие вопросы.
Раскрывать особенности MatrixNet я буду при помощи особенностей алгоритмов определения параметров орбиты небесного тела по короткой дуге наблюдений. Во-первых потому, что мозг человека устроен так, что он пытается объяснить что-то новое при помощи хорошо известного старого. И определение орбит мне известно более-менее хорошо. А, во-вторых, потому, что метод выбора ранжирующей функции с помощью MatrixNet математически подобен методам определения орбит. С точки зрения математики разницы между методами нет никакой и MatrixNet можно обучить определять орбиты. А так же известно, что MatrixNet используется в геологоразведке. Это возможно потому, что все эти задачи математически подобны.
Доказательство подобия методов
Итак, как устроен внутри метод определения орбит? В 1801 году Карл Гаусс вместо строгого аналитического метода вычисления орбиты только что открытой первой малой планеты Цереры предложил свой собственный метод. Он разделил массив наблюдений на 2 части. По трём наблюдениям (положениям небесного тела) он построил семейство орбит, а с помощью остальных наблюдений он отобрал лучшую из орбит, то есть ту орбиту, которая дала минимальную сумму квадратов невязок. Этот метод именуется методом наименьших квадратов (мнк).

Невязка — это разность между наблюдённым значением O некой величины и вычисленным значением этой же величины C.
Но MatrixNet, и вообще многие методы машинного обучения, устроены подобным же образом. Массив «наблюдений», а в случае MatrixNet это оценки релевантности для пар <запрос, документ> разбивают на две части: обучающую и контрольную. Дальше каким-то способом строят семейство функций решений. Сам способ получения этого семейства как в случае Гусса так и в случае инженеров Яндекса является очень сильным know-how, но для нашей беседы этот способ не представляет ни малейшего интереса – это предмет для отдельного разговора.
Заключительный этап машинного обучения – выбор решения, то есть одной функции из семейства, дающего наилучшую аппроксимацию (то есть приближение) на контрольном множестве «наблюдений». В первых версиях MatrixNet абсолютно точно выбирал ту ранжирующую функцию, которая давала минимальную сумму квадратов невязок, то есть использовался мнк. В настоящее время максимизируют pFound, но pFound как и сумма квадратов невязок является функцией от наблюдений.

Фундаментальные особенности методов
Квинтэссенция статьи. Которая вызывает максимум вопросов. Попытаюсь сформулировать максимально аккуратно.
У астронома может сложится обманное впечатление, что он занимается вычислением орбиты. Но на самом деле он занимается аппроксимацией, то есть вульгарной подгонкой вычислений под наблюдения. На вход в метод подаются наблюдения положений небесного тела, и на выходе получаются они же (положения), только уже вычисленные. Орбита определяется в качестве побочного эффекта. И далеко не всегда выбранная орбита, которая лучше всего аппроксимирует наблюдения, является лучшим приближением к реальной орбите небесного тела. Из чего я формулирую
Особенность №1: то, что наблюдаем, то и вычисляем
На вход MatrixNet подаются оценки пар <запрос, документ>. Эти оценки проставляют асессоры. Значит и на выходе MatrixNet мы имеем оценки пар <запрос,документ>. Только уже вычисленные.

Возражение: MatrixNet уже не минимизирует сумму квадратов невязок, а максимизирует pFound.
Ответ: но pFound как и сумма квадратов невязок является функцией от оценок пар <запрос, документ>:
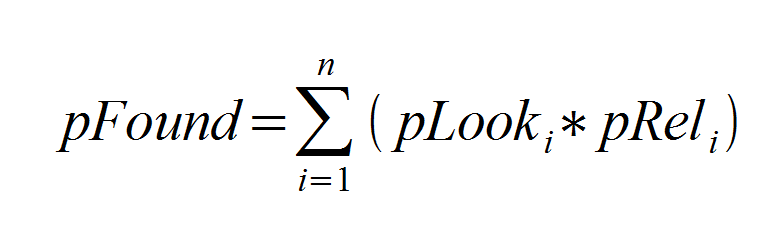
Цитата (РОМИП 2009): Значениями pRel[i] в нашей модели являются оценки релевантности по запросу.
В переводе на русский: если выбранная MatrixNet функция ранжирования хорошо угадывает оценки, которые проставляют асессоры, то pFound будет максимальным. Если же функция ранжирования угадывает оценки плохо, то вперед попадут менее релевантные сайты, а значит pFound не будет максимальным. По определению самого pFound.

Отсюда можно сделать
Практический вывод №1: необходимым (не не достаточным) условием хорошего ранжирования является соответствие документа критериям максимальной асессорской оценки (Rel+ в случае коммерческих запросов)
Если сформулировать в стиле Платона Щукина, то совет будет звучать так: делайте документы (сайты) такими, чтобы асессор (а значит и MatrixNet) мог поставить им лучшую из возможных оценок.
Вторая фундаментальная особенность методов имеет более любопытное практическое применение.
При определении орбит параметры можно разделить на две группы. Одни из них вычисляются хорошо, другие не очень.
Например, наклонение орбиты, определяется очень хорошо. Если ошибка в этом параметре большая, то вычисленные значения положения небесного тела будут чем дальше, тем больше разбегаться от наблюдаемых. Астроном может наблюдать угол наклона орбиты небесного тела относительно орбиты Земли. (Этот угол хорошо видно на первом изображении в статье, хотя из-за взаимного движения Земли и Марса получается знак зорро Z aka попятное оно же ретроградное движение; обсуждаемый угол — верхняя и нижняя планки Z).
А, например, большая полуось орбиты небесного тела вычисляется не очень хорошо. Данный параметр орбиты напрямую связан с расстоянием от Земли до небесного тела (если формулировать более аккуратно, то с расстоянием от Солнца до небесного тела, но зная расстояние от Земли до Солнца мы можем легко перейти от одного расстояния к другому). Но это расстояние на короткой дуге движения наблюдать невозможно. Перехожу к формулировке:
Особенность №2.1: параметры аппроксимирующей функции (орбиты, ранжирования), которые можно явным или косвенным образом наблюдать, имеют максимальную корреляцию (оказывают максимальное влияние) с результатом вычислений (положениями, оценками)
Особенность №2.2: параметры аппроксимирующей функции (орбиты, ранжирования), которые нельзя непосредственно наблюдать, можно варьировать в максимальном диапазоне допустимых значений без оказания существенного влияния на результат

Эти утверждения лучше всего проиллюстрировать на конкретных примерах.
- Асессор может наблюдать ассортимент магазина, поэтому можно утверждать, что магазины с малым ассортиментом не могут получать максимальные оценки (Rel+) от асессоров, а следовательно MatrixNet не может научиться хорошо ранжировать такие магазины.
- Асессор не наблюдает даты создания документов, поэтому MatrixNet может ранжировать одинаково высоко старые и новые документы
- Асессор не наблюдает тИЦ домена, поэтому MatrixNet может ранжировать одинаково высоко документы с как с доменов с большим так и с малым тИЦ
- Асессор наблюдает частоту использования запроса в документе, поэтому документы с малой частотой использования будут оцениваться как малорелевантные (Rel-), но документы со сверхбольшой плотностью могут расцениваться как спамные (Spam)
Возражение: это всё ерунда, потому что машинное обучение как раз и позволяет находить не самые очевидные зависимости между оценками асессоров и параметрами документов.
Ответ: из учебника по машинному обучению: из статистической значимости параметра не следует адекватность модели.
Перевод на русский. Никто не запрещает устанавливать подобные зависимости. Весь вопрос в том, может ли алгоритм сам «отказаться» от этой зависимости, обучаясь ранжировать документы без неё или может ли инженер Яндекса принудительно обнулить эту зависимость. Без ухудшения pFound. Мой ответ: может легко. Потому что если асессор или живой посетитель не может наблюдать данной зависимости, то она и не может быть определяющей.
Joomla, Yandex и 403 Forbidden
Очередной пост из серии хозяйке на заметку. История уже не свежая — октябрь-ноябрьская, пишу, чтобы не забыть, да и не я один наступил на подобные грабли — авось кому и сгодится.
На одном из проектов, живущем без CMS, пришлось установить Joomla — не неё пал выбор владельца. Через некоторое время после установки самой последней версии Джумла сайт стал выпадать из индекса Яндекса.
В панели вебмастера был обнаружен рост числа исключенных документов по следующей причине:
Исключённые страницы — Ошибки на стороне сервера или сайта
HTTP-статус: Доступ к ресурсу запрещён (403)
При этом при проверке через http://webmaster.yandex.ru/server-response.xml я получал сообщение, что у меня на сервере всё хорошо.
На всякий случай отписал Платону такой вопрос:
Здравствуйте.
После перевода статичного сайта на движок Joomla возникла проблема с индексацией в Яндексе.
В логах сервера видно, что яндекс получает 403 сообщение об ошибке при обращении к любому документу сайта, включая robots.txtНо, при этом при проверке доступности страниц при помощи http://webmaster.yandex.ru/server-response.xml я вижу что проблем нет — страница загружается и код ответа 200 ОК.
Не подскажете, в чём может быть проблема?
У меня самого были мысли о каком-нибудь злобном взломе через достаточно уязвимый движок Joomla, и соответственно я ожидал наличия в php документах несанкционированных вставок, или говоря по-иноземному injection. Но очень быстро в логах были обнаружены следующие следы:
178.154.206.251 — — [18/Jun/2013:06:58:30 +0400] «GET /robots.txt HTTP/1.1» 403 280 «-» «Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)»
В общем сразу стало очевидно, что следы взлома следует искать в .htaccess, так как текстовый robots.txt не может сам себя запретить.
Но .htaccess оказался штатным джумловским. И единственное подозрительное место в нём было таким:
## Begin — Rewrite rules to block out some common exploits.
# If you experience problems on your site block out the operations listed below
# This attempts to block the most common type of exploit `attempts` to Joomla!
#
# Block out any script trying to base64_encode data within the URL.
RewriteCond %{QUERY_STRING} base64_encode[^(]*\([^)]*\) [OR]
# Block out any script that includes a <script> tag in URL.
RewriteCond %{QUERY_STRING} (< |%3C)([^s]*s)+cript.*(>|%3E) [NC,OR]
# Block out any script trying to set a PHP GLOBALS variable via URL.
RewriteCond %{QUERY_STRING} GLOBALS(=|\[|\%[0-9A-Z]{0,2}) [OR]
# Block out any script trying to modify a _REQUEST variable via URL.
RewriteCond %{QUERY_STRING} _REQUEST(=|\[|\%[0-9A-Z]{0,2})
# Return 403 Forbidden header and show the content of the root homepage
RewriteRule .* index.php [F]
#
## End — Rewrite rules to block out some common exploits.
По всему выходит, что робот Яндекса каким-то непостижимым образом трактовался как эксплоит. Тем временем от Платона подоспел такой вот ответ:
Здравствуйте, Артем!
На запрос страниц сайта Ваш сервер возвращает роботу HTTP код 403, в связи с этим они не могут быть проиндексированы и временно не участвуют в поиске.
По вопросу возникновения и устранения этой проблемы, пожалуйста, обратитесь к администратору Вашего сайта или сервера.
Если ошибка больше возникать не будет, то страницы по мере обхода сайта роботом будут проиндексированы и с последующими обновлениями поисковых баз смогут появиться в поиске.Форма проверки ответа в панели Яндекс.Вебмастер может не выявить проблему, так как лишь имитирует работу индексирующего робота и имеет IP-адрес, отличающийся от IP-адреса робота.
—
С уважением, Платон Щукин
Служба поддержки Яндекса
http://help.yandex.ru/
В переводе на русский ответ означает: сервис в панели Яндекс.Вебмастер у нас есть, но он нерабочий. И коль назвался администратором веб-сервера, то сам и выкручивайся. Что хоть и обидно, но справедливо 🙂
А выкрутился я так. Для начала закомментировал в .htaccess весь блок борьбы с эксплоитами. Для тех кто не знаком с синтаксисом .htaccess — строка комментируется при помощи знака # в начале строки. Что в общем-то помогло — документы стали возвращаться в индекс.
Но после я и вовсе вместо Джумлы поставил Вордпресс. Так, на всякий случай 🙂
Аминь.
Гадкий Я(ндекс) и rel=canonical
Пост из серии хозяйке на заметку. Без выдающегося анализа и далеко идущих выводов 🙂
Предыстория
Жил был блог. Этот. За 8 лет его существования я написал 300 записей. Эта будет 301-ой. Не все из них достойны индекса. Более того, недавно я сам почистил блог от некоторого количества лытыдыбра.
С учётом всякой вспомогательной чешуи от вордпресса, всего образовалось около 1300 страниц. Это категории, архивы по годам, ссылки на которые я тоже решил удалить. И метки, которые я наоборот, решил завести. И умеренно их расставил. А главное, совсем уж мусорные страницы.
Например, каждый комментарий на странице порождает её дубликат с параметром вида replytocom=126675, который нормальному посетителю недоступен. Потому что это вспомогательная ссылка для ответа на предыдущий комментарий, а не на всю заметку. И при включенном JavaScript, перехода по ссылке не происходит.
История
Поисковикам иногда не хватает мозгов (они заняты более важными расчётами), чтобы среди нескольких дубликатов одного и того же документа выбрать главный. Из-за этого они тащат всяку каку в рот в индекс.
А поскольку я всё-равно уже установил плагин, который умеет расставлять на страницах вордпресса тэг с атрибутом rel = «canonical», я решил помочь поисковикам и воспользовался данной возможностью плагина.
Закончился мой альтруизм в борьбе за чистоту индекса весьма непредсказуемо.
Результат
Гугль, пожалуй что и не заметил данной разметки. По крайней мере пока. А вот Яндекс прореагировал очень бурно.
Внезапно оказалось, что для Яндекса установка rel = «canonical» на странице является не мягким аналогом 301-го редиректа, а просто запретом на индексацию:
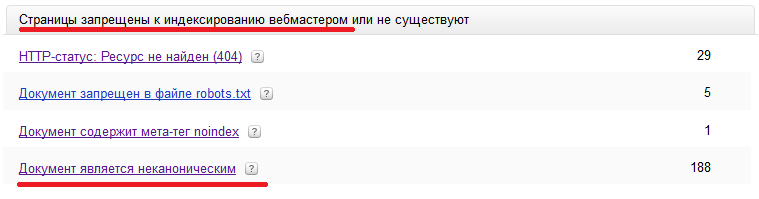
В результате, вместо неспешной замены неканонических версий документов на канонические, Яндекс тупо выплюнул все неканонические почти все документы c rel = «canonical» изо рта индекса:
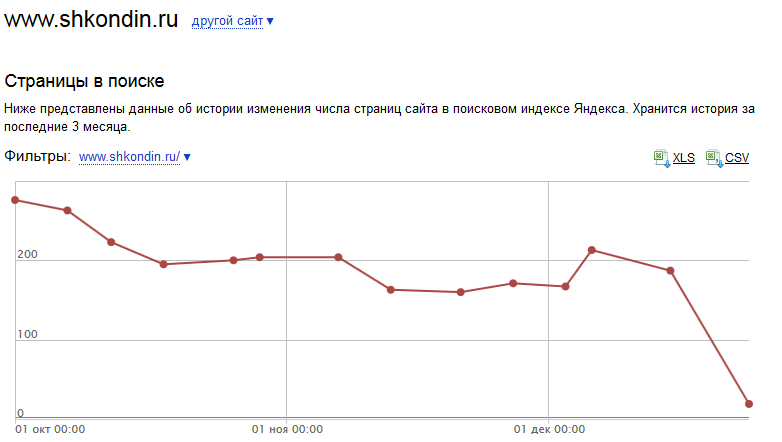
В итоге в индексе осталось 19 страниц по выдаче и 22 страницы по вебмастеру. Из примерно 200 страниц, которые ранее Яндекс считал нормальными.
При этом я, как автор, считаю, что примерно с десяток документов оставшихся в выдаче можно было бы и выкинуть (архивные вспомогательные страницы) без потери качества, а взамен разместить десяток статей, которые вызывали и вызывают реальный интерес у аудитории блога.
Вместо выводов
Маленькие дети,
ни за что на свете
не ходите Яндексу помогать.
…
Гадкий, нехороший, жадный Бармалей.
I love Yandex
Пост навеян размышлениями разных покупателей ссылок, по недоразумению считающих себя оптимизаторами, на тему, что яндекс плохой-плохой, пилит не тех сук, и всё испортил и изменил (изменит) рынок SEO. Некоторые даже намекают о своём уходе с рынка SEO-услуг. Ужос-ужос 🙂
Весь сыр-бор собственно вот из-за этого:
За последний месяц был произведен ряд изменений в поисковом алгоритме, чтобы существенно ограничить влияние SEO-ссылок на ранжирование. В первую очередь это относится к SEO-ссылкам с сайтов, содержащих некачественный контент, и к недавно появившимся SEO-ссылкам.http://webmaster.ya.ru/replies.xml?item_no=8512
Это утверждение я хочу разобрать что называется по косточкам. Проанализировать, если выражаться иноземным языком.
I Влияние SEO-ссылок с УГ сайтов ограничено
Это означает, что:
- Возросло влияние SEO-ссылок с не-УГ (СДЛ) сайтов.
- Возросло влияние не SEO-ссылок (естественных) с не-УГ (СДЛ) сайтов.
- Возросло влияние не SEO (естественных) ссылок с УГ сайтов.
И, сюрприз, сюрприз
II Влияние новых SEO-ссылок ограничено
Это означает, что:
- Возросло влияние старых SEO-ссылок
- Возросло влияние старых не SEO(естественных) ссылок
- Возросло влияние новых не SEO(естественных) ссылок
И, сюрприз, сюрприз:
Ну, а теперь сделаем ещё одно действие, которое очень многие сегодня забывают делать, и которое зовётся красивым иноземным словом синтез:
Из I и II следует, что новые и старые естественные ссылки с СДЛ сайтов рулят, как никогда раньше.
Кстати, яндекс любезно рассказал какие сайты плохие, а какие хорошие.
Вышеизложенное — это не более чем демонстрация использования алгебры логики. Подобные выводы мог озвучить любой, отучившийся на первом курсе нормального технического вуза. А теперь чуть-чуть логики оптимизаторской.
Если ограничивают влияние ссылок, сиречь внешних факторов, значит возрастает влияние внутренних факторов. Тут тем палить особо не буду. Гуглите в Яндексе тошноту по Минычу, и читайте Яндексоидов
N.B: для случайных мимохожих, любящих писать, что это понты а ля для searchengines: даю ссылку на псто от 2 ноября 09 года. Задачи поставлены, задачи решены. А конкурентов учат во всяких академиях и на семинарах.
P.S: про конверсию псто закончу чуть позже — сбор примеров идёт не быстро.
Про алгоритмы яндекса: Снежинск? Обнинск? Матрикснет!
Давненько не брал я в руки шашки, т.е. не писал про поисковые алгоритмы. Исправляемсо.
Текущий алго называется Обнинск. Зимний — Снежинск. А что за ЧУДО, которое выдавало женскую обувь 44 размера на запрос аренда электростанций, и оканчивалось на О после снежинска и перед обнинском я даже и не в курсе. Не до названий было. Процесс полной адаптации к Матрикснет занял у меня кучу времени (8 месяцев, видимо старею :() и де факто обошёлся в кругленькую сумму с 5 ноликами и не одной единичкой впереди недополученной прибыли. Потерянные нервные клетки не считал, благо согласно современным исследованиям они всё-таки восстанавливаются.
К слову, миль пардон (тысячи извенений) тем, кому в процессе растраты мной нервных клеток не посчастливилось подвернуться под горячую руку. И ещё раз повторю: проститедяденькузасранца. В следующий раз держитесь подальше 🙂
В результате, вот какие факторы ранжирования у меня выкристаллизовались (привожу не по важности, а по мере вспоминания, не обессудьте 🙂 )
- спамность текста документа
- размер документа ( если сложить 1+2, то можно вспомнить о «тошноте» по минычу)
- спамность анкор-листа
- размер анкор-листа (3+4 определяют SEO-прессинг)
- возраст ссылок
- возраст документа
Как следствие, в данное время наблюдаю достаточно любопытный феномен: лобовые действия оптимизатора как правило вредят ранжированию. Зато у «простых вебмастеров» появилась возможность добиваться хороших результатов десятком-другим «естественных» ссылок. Надо нанести точечный удар и подождать полгода (некоторые мои зимние эксперименты дали феноменальный результат, если ориентироваться на нулевые затраты на ссылки).
Ну вот, типа поплакался и похвастался заодно. На душе и полегчало. А как долго вы адаптировались к Снежинску?