Ван-ту, ван-ту: чек да майкрофон.
В последнее время я слегка опаздываю за новостями Яндекса. И, хотя, на первый взгляд они кажутся эпохальными (два объявления об изменениях в алгоритме, кастрирование языка запросов), после некоторых раздумий выясняется, что это далеко не так. Вот небольшой мыслестрептиз по поводу безвременной кончины операторов link и anchor:
- Мысль первая, паническая: Шеф, усё пропало! Гипс снимают, клиент уходит!
- Мысль вторая, конспирологическая: это проделки
Фиксаходоков на теплоходе — типа так началось строительство цивилизованного рынка. Мысль навеяна вот этим высказыванием:
Руководство Яндекса, в лице Ильи Сегаловича, Елены Колмановской и Александра Садовского, сообщило об этом на встрече с несколькими оптимизаторами, которая прошла в неформальной обстановке в одном из московских ресторанов.
NB(для тех кто в танке): на теплоХОДе не плавают, а ходят, потому и ходоки 😉
- Мысль третья, разумная: всегда существует несколько способов проверить проиндексирована ли конкретная ссылка поисковой системой. Например, очевидно, что проиндексированная ссылка будет находится в кэше.
- Мысль четвёртая, программерская: как ни откладывай, а скрипт, который считает количество ссылок на заданный сайт с определённым словом в анкоре написать таки придётся.
После этого мысли моей голове расплодились в катастрофических объёмах, а посему из гуманных соображений я решил не грузить вас потоком сознания 😀
P.S: если у вас есть интерес к упомянутому выше скрипту — дайте знать в комментах на сколько он вам интересен.
На апдейт алгоритма Яндекса
Я, конечно, слегка нарушаю собственные же правила, делая выводы не дождавшись одного-другого апдейта по новому алгоритму, но, тем не менее, придам гласности ма-а-аленькое наблюдение: все изменения алгоритма Яндекса очень хорошо укладываются в теорию TrustRank‘а.
Судите сами:
- По многим коммерческим однословным запросам из выдачи исчезли внутренние страницы. Например, по кондиционерам две-три таких страницы прокрались в начало выдачи только с начала этого года, аккурат после начала массового использования
линкаторов нового типассылочных брокеров. - При этом на коммерчески непривлекательных запросах видно, что наиболее релевантными считаются не самые прокачанные страницы, а морды этих же сайтов, т.е. наиболее авторитетные страницы. Так, например, по одному из моих любимых запросов (SEOBar) Яндекс выбрал самой релевантной морду этого домена, тогда как наиболее прокачанной страницей домена согласно Google Webmaster Central является http://www.developing.ru/seobar/ (это действительно так — домен по каталогам не прогонялся, а вот страница тулбара попала в какое-то софтверно-варезное кольцо(сетку?) плюс имеет приличное количество естественных ссылок), да и обычная релевантность морды оставляет желать — единственное упоминание термина — в исходящей ссылке.
- При этом, по многим запросам в топ стали пробиваться страницы (в том числе и внутренние) авторитетных сайтов: вики, «каталог» рамблеровского ТОП100, газеты (я чаще наблюдаю морды) и даже морды Рамблера и Гугля (как найденные по ссылке)
Как обычно, disclaimer: автор не делал свои выводы на основании анализа только двух запросов, однако вполне отдаёт себе отчёт в том, что всё вышеизложенное может являтся не более чем совпадением
А вы что думаете о новом алго?
Конец эры GoogleBombing’а?
Матвей отрапортовал об вводе в строй алгоритма, который призван бороться с GoogleBombing’ом. Я, как и каждый оптимизатор, разумеется задался мыслью, а как бы я устроил данный фильтр? Мне в голову пришли такие варианты:
- ручная фильтрация
- понижение релевантности страниц, не содержащей искомой фразы
- понижение релевантности страниц, на которые ведёт большое количество маловариативных ссылок
- комбинация 2 и 3
Немного поясню пункт 3. Если на страницу идут ссылки исключительно с текстом windows rulez, то это плохо, потому как в натуральных условиях на страницу почти наверняка будут вести также ссылки windows rulez forever, а также windows suxx и windows must die, ну и конечно же просто windows.
Фанатики Гугля скажут, что ручной фильтр и Гугль несовместимы. Возможно. Но по крайней мере биография Буша по запросу miserable failure похоже что зафильтрована именно руками. Если сделать поиск точной фразы по сайту Белого Дома, то мы обнаружим, что 14 из 17 страниц скрыты в «похожих». Ага. Особенно похожа на три англоязычные страницы биография Буша на испанском! Так что алгоритм алгоритмом, но почему бы и не подстраховаться? 🙂
Микротест качества поиска
Запрос учёный года. По умолчанию подразумевается 2006-й год. Правильный ответ — Перельман. Его даёт только Гугль.
Реальный PageRank
Отстал тут маленько от жизни. Оказывается, Гугль показывает в своих Webmaster Tools историю страниц с самым большим PageRank. Как и следовало ожидать, самая пиаристая страница на моём сайте http://www.developing.ru/seobar/ , а вовсе и не морда с тулбарной 4-кой. Жаль, что показывает только одну страницу и без численного значения.
Webalta умерла не родившись?
Что-то вспомнилось, что был такой поисковик Webalta, о котором шумели многие сетевые СМИ в конце лета. Захотелось посмотреть, как обстоят дела у него с популярностью. Открыл статистику LI.ru и увидел такую картину:
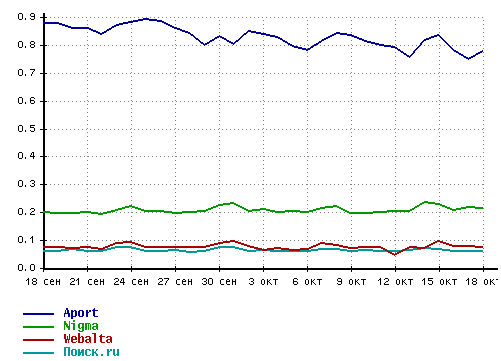
По-моему, с каждым днём становится всё очевиднее, что это такой же мёртворождённый проект, как, например, turtle.ru. Кстати, его создатель Дмитрий Крюков ищет работу.
Автоматизированный отлов дорвеев
Гугль кооперируется с Википедией на предмет отлова спаммерских ссылок.
Идея логична. Вики спамят в промышленных масштабах и доры можно отстреливать на подлёте. Собственно логично и объявление о кооперации — оно само по себе уменьшит объёмы спама в Вики.
А мне вот что подумалось. Формочка в Яндексе (или кнопочка в баре для FF от Яндекса) «пожаловаться на спам» не очень полезна. Определение спама для поисковика весьма и весьма субъективно. Лично мне пользоваться этой формочкой некомфортно по моральным соображениям 🙂 Я если и стучу на доры, то сразу на кучу однотипных, отправляя Александру Садовскому ссылку на запрос в Яндексе. На большой коллекции можно и алгоритм подкорректировать. Но! Я точно знаю, где я не буду ощущать никаких душевных терзаний определяя спам это или нет. В собственном блоге и форуме. В движке WordPress’а при модерации комментариев есть опция — пометить как спам. Нужно всего лишь дописать функцию, которая будет заодно сливать в Яндекс (Гугль, Рамблер) эти спаммерские сообщения. Или складывать их в одном месте, доступном в том числе и поисковикам. Подобный мод можно сделать и для других блогов и форумов на популярных движках. Работы не много, а информации для анализа будет море. Я даже с удовольствием размещу на форуме и блоге кнопочку: весь спам автоматом перенаправляется в поисковики.
Конечно, спамеры попытаются зафлудить такой механизм ложными жалобами, т.е. будут спамить в блоги и форумы нормальные сайты. Так что примитивный алгоритм «раз спамит, то в бан» не подойдёт. Но, нормальные сайты тем от доров и отличаются, что они друг на друга не похожи. Так что таким макаром можно будет вычистить как минимум типовые доры. Да и плюс одно дело спамить собственные ресурсы, зная, что расходы на спам окупятся, и совсем другое — спамить забесплатно чужие ресурсы. Так что поток «ложного» спама будет существенно меньше спама натурального.
Ну и в продолжение темы. Кроме отлова доров с помощью чужих ресурсов можно их отлавливать и на своих собственных. Более чем уверен, что комментарии, которые удаляют блоггеры на BlogSpot.com (Blogger.com) подвергаются Гуглем тщательному анализу. Если добавить немножко конспирологии, то Яндекс запросто мог создать с десяток каталогов и вычислять автосабмитеров по факту попадания во все эти каталоги…
Уточняющие запросы (refinements) в Гугле
Возможно, это уже и не новость, но оказывается по некоторым однословным запросом Гугль выдаёт список уточняющих запросов. Например, если ввести название города.
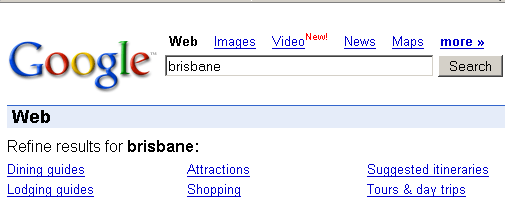
При переходе по ссылке Гугль добавляет к запросу квантор more, так, например, запрос brisbane преобразуется в brisbane more:shopping или brisbane more:sightseeing (хотя ссылка называется attractions).
Как обычно, буду благодарен за примеры других типов запросов с refinements.