Некоторые синтетические поведенческие факторы ранжирования Яндекса.
Если ты воздействуешь на поведенческие факторы естественным или искусственным способом, то данная заметка поможет тебе понять в правильном ли направлении ты двигаешься.
На этот раз почти никакой отсебятины — список синтетических поведенческих факторов опубликован по доброй воле Яндекса в докладе Through-the-Looking Glass: Utilizing Rich Post-Search Trail Statistics for Web Search.
Самим Яндексом статья датируется 1-м сентября 2013 года. Была представлена на конференции CIKM 2013, проходившей с 27 октября по 1 ноября 2013 года в Бёрлингейме (США)
На сайте Яндекса упоминание доклада есть, но самого текста до сих пор нет. Поняли, что сболтнули лишнего? 🙂
NB: Выражаю благодарность Илье Зябреву AlterTrader Research ltd за предоставление текста доклада.
Поведенческие факторы ранжирования Яндекса
QueryDomCTR — среднее значение CTR всех документов домена по данному запросу
QueryUrlCTR — среднее значение CTR конкретного документа по данному запросу.
QDwellTimeDev — стандартное отклонение (девиация) от среднего времени пребывания на документе по запросу. Может применяться для отсеивания накруток ПФ.
QDwellTime — этот параметр в докладе не упоминается, но он очевидно используется как фактор ранжирования . Т.к. если мы считаем стандартное отклонение для случайной величины, то должны знать и матожидание (оно же среднее значение) этой величины. Соответственно это среднее время пребывания посетителя на документе по запросу.
AvSatSteps — среднее количество удовлетворённых шагов по сайту. Удовлетворённый шаг — переход по внутренней ссылке после 30 секунд пребывания на документе. Важно, что среднее значение таких шагов всего ~0.2 и меньше на домен не зависимо от тематики сайта.
NB: Как следует из данного доклада Яндекс «знает» к какой тематике принадлежит страница сайта. На основании собственного набора доменов второго уровня с вручную определёнными тематиками (я так понимаю это ни что иное как Я.Каталог, возможно расширенный за счёт Dmoz.org) и c помощью наивного байесовского классификатора любой документ из индекса приписывается к той или иной тематике.
AvDwellTime — общее среднее время пребывания посетителя на документе по разным поисковым запросам.
DwellTimeDev — стандартное отклонение (девиация) времени пребывания на сайте. Так же может использоваться для отслеживания накруток ПФ.
90thDwellTime — это верхний дециль, он же 90-й персентиль среднего времени пребывания на сайте. Позволяет отбрасывать накрученные AvDwellTime и QDwellTime.
10thDwellTime — это нижний дециль среднего времени пребывания на сайте. Позволяет определять дорвеи. Очевидно, что Яндекс ожидает от «белых» вебмастеров улучшений именно тут.
TimeOnDomain — общее время пребывания на сайте. По всем запросам любых документов.
CumulativeDev — стандартное отклонение (девиация) от среднего времени пребывания на сайте
Несколько ехидных замечаний
- Ты боишься, что накрутка ПФ снижает конверсию и это негативно влияет на ранжирование? Не гневи SEO-бога — Яндекс умеет считать только satisfied steps. О конверсии он даже не помышляет. Я уже пытался объяснить почему.
- Чтобы удовлетворить инженеров Яндекса тебе следует крупные статьи разбивать на маленькие. Очень маленькие. Потому что средний человек читает менее 300 слов в минуту. А инженеров интересует клик через 30 секунд. К этому моменту ты прочитал уже примерно 300 слов в этой небольшой заметке. Для сравнения, хорошей обзорной статьёй считается заметка длинной минимум в 1000 слов.
- По той же причине тебе не следует размещать ни внутренних, ни тем более внешних ссылок в начале документа. Чтобы не было неудовлетворённых переходов.
Вместо заключения
Данный доклад Яндекса замечательно объясняет, почему не работает накрутка поведенческих факторов ранжирования по 3-4 запросам. А именно такое количество запросов пытается накручивать обычный (медианный) оптимизатор. Средний — всего 9. Успешный же оптимизатор накручивает в среднем от 40 запросов и выше. Только так можно заметно повлиять например на AvDwellTime и TimeOnDomain.
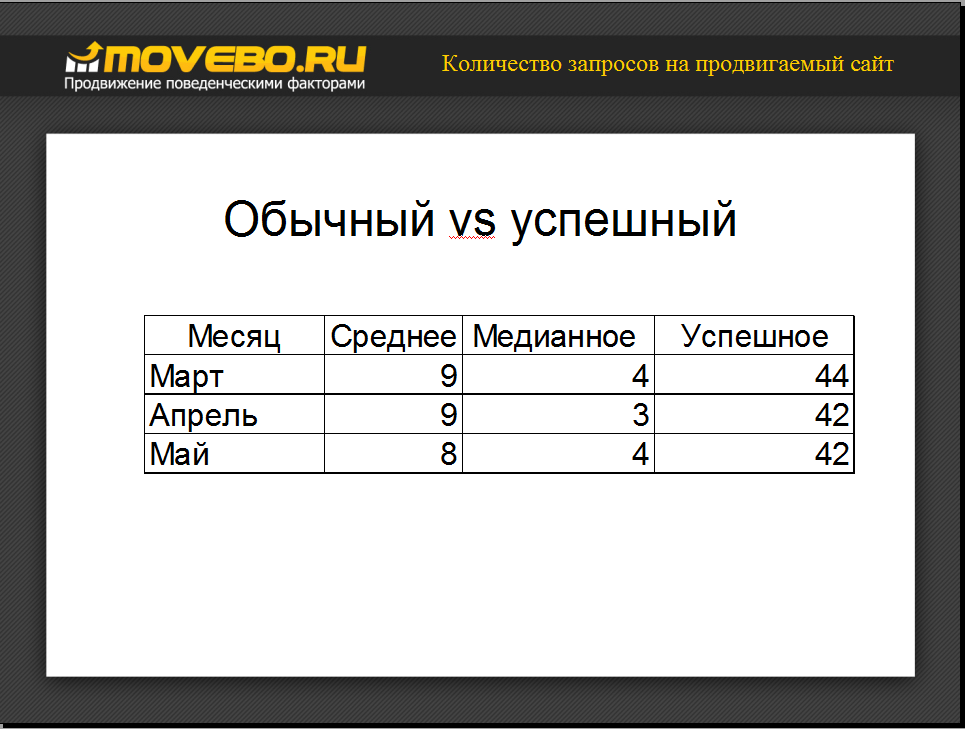
Эти данные я приводил в июне 2013 года на конференции по конверсии. Но тот доклад видимо было воспринят исключительно как реклама сервиса.
http://www.youtube.com/watch?v=qy61DRegtN0
Непосредственно о ПФ я сбивчиво и путано бормочу с 15:44. Из этого же видео можно узнать о чём я собирался рассказывать в III части списка ПФ. Которую я как-нибудь всё-таки изложу и в письменном виде 🙂
Как теперь стало понятно, инженеров из Яндекса я переоценил — работа над улучшением конверсии снижает количество удовлетворённых шагов, но мужики-то об этом не знают (ц)!
А что ты думаешь о засвеченных в докладе Яндекса поведенческих факторах и естественных или не очень способах воздействия на них?
Полный список ПФ. Часть II. Отказы.
Продолжаем исследовать поведение пользователя. Мы остановились на том, что посетитель перешёл на сайт. Всё его поведение на сайте описывается двумя параметрами: длительность сессии и количество просмотренных страниц. В этот раз мы рассмотрим дальнейшие действия посетителей.
Отказы
После того, как посетитель сайта завершает с ним своё знакомство, возможны три варианта дальнейшего развития событий. Которые в веб-статистике именуются при некоторых условиях термином Bounce (Отказ) и в таком же виде перекочевали в терминологию оптимизаторов.
Переход на другой сайт
Ставлю переходы на другие сайты на первое место, потому что имею все основания считать что именно с фиксации таких переходов и началась эра использования ПФ в поисковиках.
Дело в том, что классический дорвей как раз характеризуется автоматическим редиректом на сайт рекламодателя. То есть за переходом на сайт из выдачи следует быстрый переход на новый домен.
Точно так же сайт сделанный для продажи рекламы (в дальнейшем MFA-сайт) будет характеризоваться повышенным количеством переходов на сайты рекламодателей.
В принципе, документ энциклопедического качества в обязательном порядке ссылается на первоисточники. И по этим ссылкам возможны переходы в большом количестве. Поэтому снова возникает соблазн оценивать качество документов временем, потраченным на знакомство с ним. Однако, в этом нет необходимости, что мы увидим чуть ниже.
Завершение поисковой сессии
Следующее действие, которое может совершить посетитель на оцениваемом документе — просто закрыть браузер. Это событие фиксируется по отсутствию какой либо иной активности посетителя.
Это действие конечно можно расценить как отчаяние посетителя найти что-либо подходящее в интернете, но в действительности это поведение оценивается прямо противоположным образом. Посетитель нашёл то, что искал и именно по этой причине прекратил дальнейшие поиски.
Возврат на поисковую выдачу
Последний вариант «отказа» — это возврат на поисковую выдачу. Это самый мощный поведенческий фактор оценки качества документа. Если подавляющее большинство посетителей заканчивает свои поиски на оцениваемом документе, то документ хороший. Если продолжает – то не очень.
Пример хороших документов представить не сложно. Для большинства информационных запросов на документах из википедии будет заканчиваться большинство поисковых сессий.
Возврат на выдачу так же позволяет оценить переход на другой сайт. Если возврата на выдачу нет, то переход был на уточняющий сайт, первоисточник. А вот если возврат на выдачу произошёл, то поисковик поставлен перед таким фактом: сразу два документа не удовлетворили чаяний пользователя. А это значит, что оцениваемый документ имеет крайне низкое качество. Потому как не удовлетворяет пользователя ни сам, ни при помощи «первоисточников».
Именно по этой причине поисковики не рекомендуют размещать на сайтах назойливую рекламу, особенно попапы и попандеры. Поисковик фиксирует запрос к ещё одному ресурсу. С учётом того, что попап провоцирует повышенное количество возвратов в поиск, документ практически гарантированно потеряет в позициях. Даже если изначально он оценивался как весьма релевантный. И борьба за «чистоту» интернета тут вовсе не причём 🙂
Вместо заключения
На этом мы закончили знакомство с типовыми ПФ. Теперь вы знаете, что сайт сделанный для людей это не тот сайт, на котором посетители просматривают кучу страниц и тратят кучу времени на поиск нужной информации. А тот сайт, на котором завершается большинство поисковых сессий посетителей.
Это была самая скучная, формальная часть списка ПФ. Дальше пойдёт самое вкусное — поведенческие факторы, которые действительно сильно влияют на ранжирование.
В качестве домашнего задания крайне рекомендую посмотреть запись выступления Дмитрия Иванова, руководителя отдела «Телемакс» на веб-семинаре Мовебо. Это рассказ об эксперименте по накрутке поведенческих факторов магазина бытовой техники с помощью подписчиков группы Вконтакте.
После просмотра попытайтесь определить главные условия успеха эксперимента. Отсутствие возвратов на выдачу — только одно из.
PS: скучаю по вопросам в комментариях 🙂
CTR сниппета и обратная положительная связь
Закрываем тему влияния CTR сниппета на позиции по запросу строгим доказательством…
1. Предположим, что CTR сниппета документа, отображаемого пользователю в ответ на его запрос, влияет на ранжирование этого документа по этому запросу.
2. Значит для низкоконкурентных запросов, где основной вклад в общую релевантность даёт текстовая составляющая, влияния CTR сниппета должно быть достаточно для перехода документа с n+1 позиции на n позицию выдачи.
3. Но при переходе с n+1 позиции на n позицию CTR сниппета вырастет, так как он сильно зависит от занимаемой позиции (как именно — см. напр. тут)
4. Как следствие, со временем все низкоконкурентные выдачи должны упорядочиваться по убыванию CTR документов.
5. Поскольку в выдаче любого поисковика по малоконурентным запросам в топ10 полно документов со сниппетами, явно уступающими по качеству нижестоящим документам, то утверждение из п.1 не верно.
… и простой брутальной логикой:
Плохой документ (дорвей или документ с MFA-сайта) может иметь хороший сниппет. Поисковику не имеет смысла поощрять в выдаче плохие документы 🙂
Вывод: влияния CTR сниппета не достаточно для ранжирования даже по низкоконкурентным запросам.
NB: при этом CTR сниппета вполне может быть запросонезависимым фактором. Если совокупность всех сниппетов по всем запросам для сайта лучше (их взвешенный CTR больше), значит и сайт лучше, чем другие. И вот этот средневзвешенный CTR всех сниппетов может оказывать уже достаточно заметное влияние на ранжирование.
Чуть позже я покажу куда более сильные ПФ, по которым можно оценивать качество документов, сайтов и бизнесов, стоящих за этими сайтами.
Поведенческие факторы: CTR сниппета
Заметка впервые опубликована в блоге Сергея Кокшарова
Это слегка переработанная версия.
Есть ли место для парадокса?
Один из красиво сформулированных SEO принципов гласит:
Относитесь к сниппету документа в SERP’е как к объявлению в контекстной рекламе
Смысл реализации этого принципа заключается в том, чтобы оптимизатор добивался появления в SERP’е сниппета привлекательного для человека. А не для поискового робота, как это происходит зачастую.

Этот же принцип можно переформулировать так: повышайте кликабельность (CTR) ваших сниппетов. Я стараюсь придерживаться этого принципа сам и советую это делать другим.
Это с одной стороны.
А с другой стороны я берусь утверждать, что CTR сниппета не влияет (ну или почти не влияет) на ранжирование документа. С первого взгляда между этими двумя утверждениям есть некоторое противоречие. Давайте попробуем вместе разобраться в этой, казалось бы, запутанной ситуации.
Кто виноват в плохом сниппете?
Разумеется основой для составления сниппета является текст документа, ответственность за который полностью лежит на авторе. Но уже корёжит этот текст именно поисковик.
Если вы занимались контекстной рекламой, то скорее всего знаете, что на CTR текстового объявления может повлиять даже такая, казалось бы, мелочь, как знак пунктуации в конце предложения. Из знаков на CTR особенно сильное влияние оказывает знак многоточия. И именно этим знаком больше всего любят злоупотреблять поисковики. Я уже не говорю о совсем неудачных случаях, когда в сниппет попадают технические блоки информации, вроде меню.
Таким образом, качественный документ может иметь низкую кликабельность в выдаче только потому, что поисковик составил для него неудачный сниппет. И наказывать за собственное неудачное действие как минимум не очень логично.

К слову, использование в качестве сниппетов документов каталожных описаний является прямым свидетельством того, что поисковики до сих пор не умеют составлять качественные сниппеты. А CTR сниппета используется в первую очередь для сравнения сниппетов между собой. Если для документа поисковик не может составить кликабельного сниппета, он прибегает к спасительной соломинке в виде описания, подготовленного редактором каталога, то есть человеком.

От теории к практике — расширенные сниппеты
Опять же из практики использования контекстной рекламы хорошо известно, что объявление с дополнительными ссылками имеет больший CTR, чем обыкновенное объявление с тем же текстом. При этом мы знаем (из справки вебмастера), что Яндекс показывает быстрые ссылки только для трех самых релевантных документов.
А в выдаче как мы видим, самый релевантный документ, улучшенный заведомо более кликабельным, чем у конкурентов сниппетом, не попадает на первые позиции:
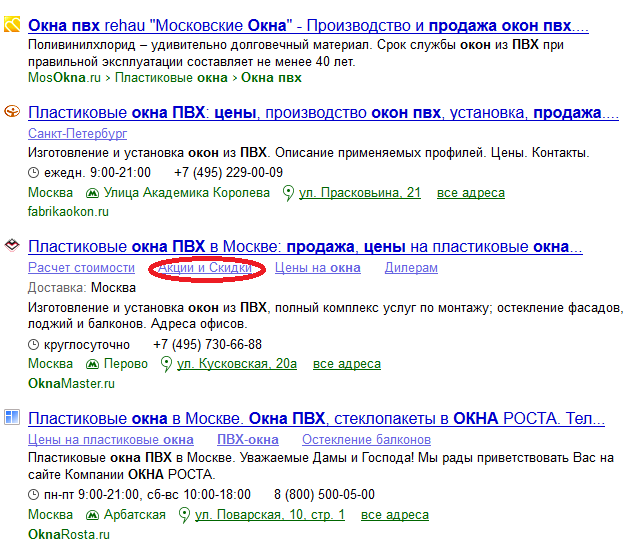
Кроме того, ссылка на скидки и акции заведомо даёт больший CTR, но не помогает второму документу с расширенным сниппетом обогнать первый с расширенным. И это при том, что у обоих документов нейтральные каталожные описания, почти идентичные заголовки и расширенный сниппет первого содержит только название дополнительного региона продаж.
Из чего следует, что CTR сниппета не оказывает заметного влияния на ранжирование документа.
Практика скрутки CTR сниппета
И наконец, посмотрим на случай явной накрутки конкурентами ПФ на своем сайте, что явилось одновременно скруткой CTR на сайте моего клиента:
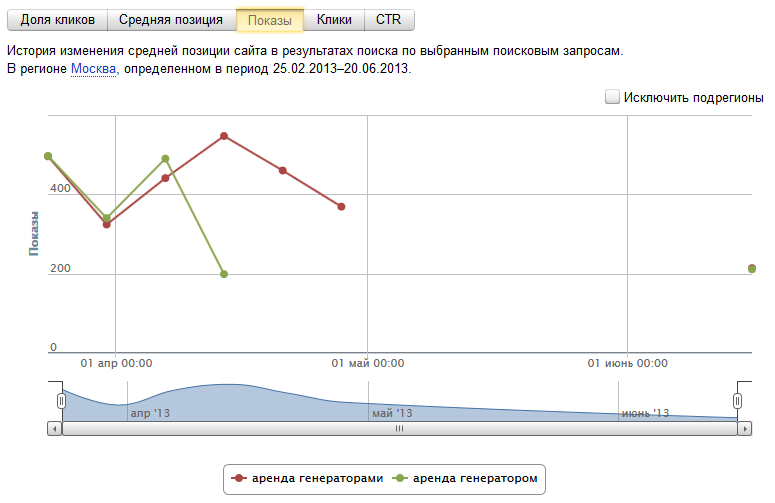
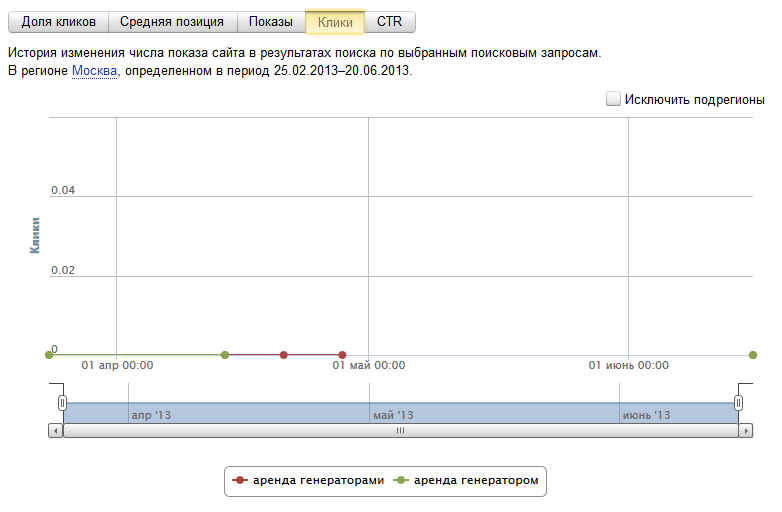

Как видим, несколько месяцев нулевого CTR на позициях существенным образом не отразилось – движение плюс минус 2-4 позиции в обе стороны.
Зачем тогда красивый сниппет?
У вас не мог не возникнуть вопрос, зачем тогда добиваться похожести сниппета на контекстное объявление. Все очень просто.
Чем привлекательнее сниппет вашего документа, тем больше посетителей перейдёт на ваш сайт из поисковой системы. И если ваш документ (или даже сайт целиком) в должной мере удовлетворит ожидания посетителей, они совершат те самые положительные действия, которые в конечном итоге скажутся на улучшении ранжирования.
Но если вы просто приобретаете клики по SERP’у, толку от этого не будет никакого.
От том, чем отличается плохое поведение от хорошего мы поговорим в следующий раз.
Полный список поведенческих факторов ранжирования. Часть I.
Полный список ПФ — это, возможно, преувеличение, поскольку поисковики могут использовать комбинации действий пользователей в качестве факторов ранжирования. Но это безусловно будет один из самых подробных перечней действий посетителей.
Список этот мне понадобился по двум причинам. Во-первых, большинство списков ПФ, которые я видел до этого, не были хоть мало-мальски систематизированы. И излагались в виде «что вижу (в Google Analytics или Яндекс Вебмастер) о том и пою».
Я же хочу упорядочить этот список по порядку возникновения действий посетителя сначала в выдаче поисковой системы (на SERP’е), потом на сайте, а затем (сюрприз-сюрприз) и тогда, когда поисковая сессия была завершена.
А во-вторых этот список нужен для того, чтобы чуть позже сравнить плохие и хорошие паттерны поведения пользователей.
Итак, поехали.
История поиска
Ещё до того, как пользователь поисковой системы совершит свое первое осознанное действие в текущей поисковой сессии, поисковик уже имеет определенное представление об этом посетителе. Потому что он хранит историю всех поисковых сессий каждого (с точностью до куки). И может на основании анализа этой истории сделать некоторые, надо сказать, довольно точные представления о поле и возрасте посетителя. И гораздо менее точно о его детальном социальном профиле.
Предполагается, что на основании этих данных, например для мужчины по неопределённому запросу кондиционер поисковик может предпочесть сайты о климатической технике, а для женщины — о косметических средствах.
Безусловно, здесь огромное поле для исследований и однозначно тут есть над чем подумать дорвейщикам и особенно MFAшникам. Но я пока буду полагать, что белым оптимизаторам нет резона заставлять сайт климатической техники мимикрировать под сайт о косметических средствах и наоборот.
Поисковый запрос
Первое осознанное действие пользователя поисковика — ввод поискового запроса. Сам по себе запрос не является поведенческим фактором, а вот совокупность запросов, заданных пользователем (см. пред. пункт) и совокупность всех запросов, для которых данный документ оказался релевантен и по которым посетители продемонстрировали поисковику, что документ уместен, таковыми факторами являются.
Поясню на примере. Электрогенераторы бывают дизельными, бензиновыми и газовыми. Если ваш документ посвящен только газовым генераторам, а посетителей интересуют в основном бензиновые и дизельные генераторы, то у вашего документа будут сложности с ранжированием по общим запросам электрогенераторы и генераторы.
Другими словами, на основании анализа поведения всех пользователей, задававших конкретный поисковый запрос, поисковик будет показывать не самый релевантный контент, а релевантный контент, пользующийся наибольшим спросом.
CTR сниппета
После того, как посетитель сформулировал свой запрос, поисковик предлагает ему на выбор несколько документов. И тут возникает соблазн посчитать отношение числа показов документа к числу кликов.
О влиянии этого отношения я написал отдельную статью. (Первоначально она будет опубликована в блоге devaka.ru) Здесь же я отмечу следующие моменты:
- Этот фактор подвержен максимальной обратной положительной связи. То есть чем выше документ в выдаче, тем чаще по нему кликают.
- Сниппетов у документа много и CTR сниппета больше всего влияет на выбор самого привлекательного сниппета, а не на ранжирование документа
-
«Плохой» документ (напр. дорвей) может иметь самый привлекательный сниппет.
Глубина и длительность сессии
Дальше посетитель покидает поисковую выдачу и переходит на конкретный сайт. Почему-то многими оптимизаторами считается, что чем дольше посетитель провел времени на сайте и чем больше страниц он просмотрел, тем качественнее сайт.
Этому заблуждению придётся посвятить отдельную заметку. Пока же отмечу, что любая статья энциклопедического качества будет иметь глубину просмотра равную единице и время просмотра равное нулю. По той банальной причине, что если не было переходов на другие страницы, то нет технической возможности определить время, которое пользователь провел на этой странице.
Так же стоит заметить, что после того, как посетитель покидает поисковую выдачу, резко падает полнота контроля за его действиями. Для этого контроля необходимо, чтобы пользователь использовал особый браузер, сигнализирующий о действиях пользователя поисковику или браузер с установленный баром, занимающимся тем же. Распространенность же Я. Метрики и Google Analytics, полагаю, всё же меньше распространенности Google Chrome, FireFox и Яндекс.Браузера.
Конверсия
Я не хотел, но вынужден упомянуть здесь про конверсию, так как многие считают, что конверсия является солью продвижения. Развернутое мнение по этому вопросу можно прочитать в статье Поведенческие факторы: Конверсия.
Продолжение следует.
Поведенческие факторы: конверсия
Проблема
На одной из конференций я услышал вот такое сомнение в целесообразности искусственного воздействия на ПФ:
Если покупать дополнительный поисковый трафик это приведет к снижению конверсии. А значит ухудшит качество ПФ. Что в конечном итоге негативно отразится на позициях
На самом деле никакой проблемы тут нет. И вот по каким причинам.
Во-первых, успешная транзакция в вебе – это всего лишь посещение определенной страницы на сайте. Например, www.site.ru/spasibo_za_pokupku.html То есть никто не мешает провести добавочных посетителей нужным нам маршрутом. И на этом можно поставить жирную точку.
Немного теории конверсии
Но давайте попробуем разобраться имеет ли смысл в принципе полагаться на такой показаталь, как коэффициент конверсии при ранжировании документа. И мы увидим следующее:
В рунете многие транзакции совершаются в оффлайне. Начиная с обсуждения условий сделки по телефону. И заканчивая оплатой товара курьеру налом. То есть факт конверсии поисковиком просто не может быть зафиксирован. Это уже во-вторых.
В-третьих, конверсия на сайте в целом редко превышает 5%. Это с учетом повторных покупателей, то есть лояльных клиентов. А многие запросы носят хоть и коммерческий, но не выраженно транзакционный характер. То есть конверсия по конкретному запросу достаточно часто менее 1%. В отличном магазине. В средних , коих большинство и которых собственно и не понятно как ранжировать после лидеров – и того меньше.
В результате поисковый алгоритм будет вынужден принимать решение о плохом или хорошем поведении на основании одной-двух транзакции. Это если ещё он имеет о ней сведения. И уж тем более не имея представления об удовлетворенности посетителя этой самой транзакцией.
А есть ли альтернатива конверсии?
Да есть. Гораздо более точный инструмент оценки не только качества сайта, но и качества бизнеса, стоящего за ним. Речь о повторных покупателях. Которых тем больше, чем лучше и сайт и бизнес.
И оценивая количество лояльной аудитории мы избавляем себя от деления сайтов на коммерческие и остальные, где конверсии как таковой может не случаться в принципе.
В следующий раз я покажу что даже CTR очень слабо влияет на позиции.